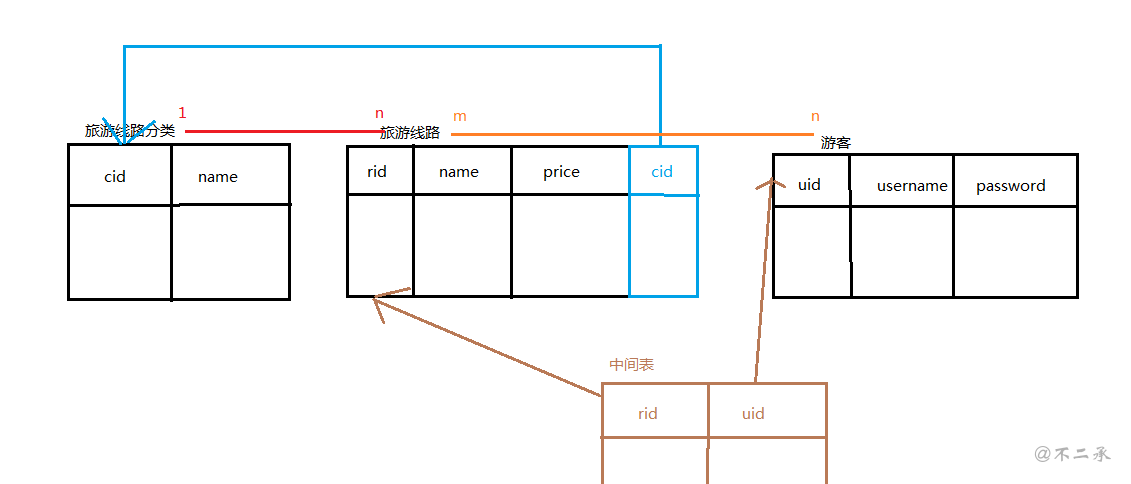
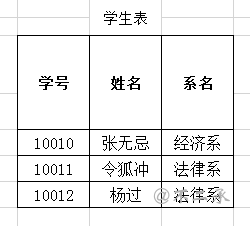
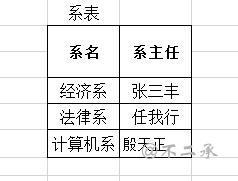
-- 创建部门表 CREATE TABLE dept( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) );
-- 添加数据 INSERT INTO dept(NAME) VALUES('开发部'),('市场部'),('财务部');
-- 创建员工表 CREATE TABLE emp( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(10), gender CHAR(1), salary DOUBLE, join_date DATE, dept_id INT, FOREIGN KEY (dept_id) REFERENCES dept(id) );
-- 添加数据 INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3); INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);
1
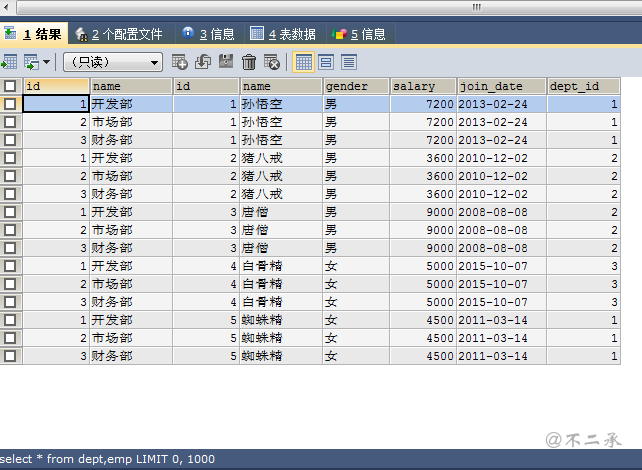
select * from dept,emp;
笛卡尔积:简单的说就是两个集合相乘的结果。
要完成多表查询需要消除无用查询。
多表查询的分类
内连接查询
组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
隐式内连接
使用where条件来消除无用查询。
1 2
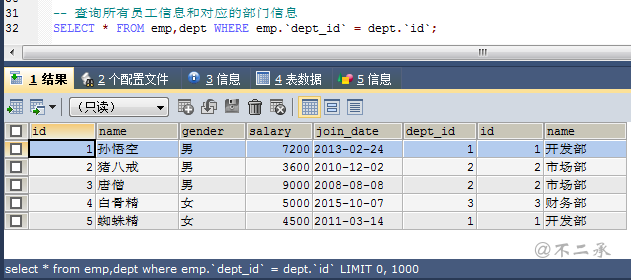
-- 查询所有员工信息和对应的部门信息 SELECT * FROM emp,dept WHERE emp.`dept_id` = dept.`id`; -- 注意,不是单引号,是大键盘1旁边的符号 ,加或不加都一样
1 2
-- 查询员工表的名称,性别,部门表的名称 select emp.name,emp.gender,dept.name from emp,dept where emp.dept_id = dept.id;
更常用的格式
1 2 3 4 5 6 7 8 9
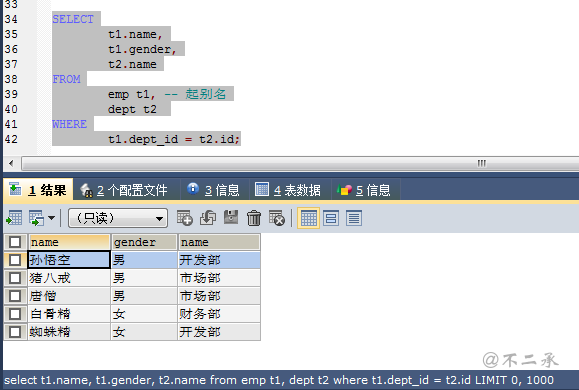
select t1.name, t1.gender, t2.name from emp t1, -- 起别名 dept t2 where t1.dept_id = t2.id;
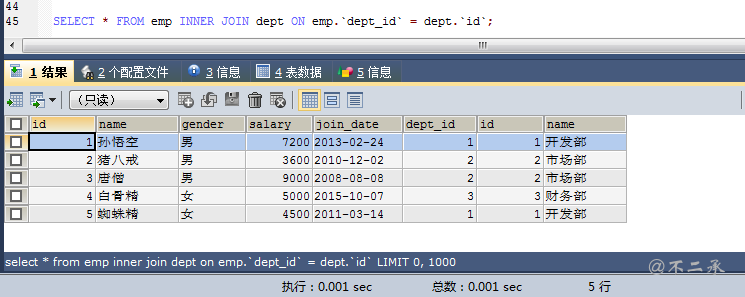
显式内连接
1
select 字段列表 from 表名1 [inner] join 表名2 on 条件;
1 2
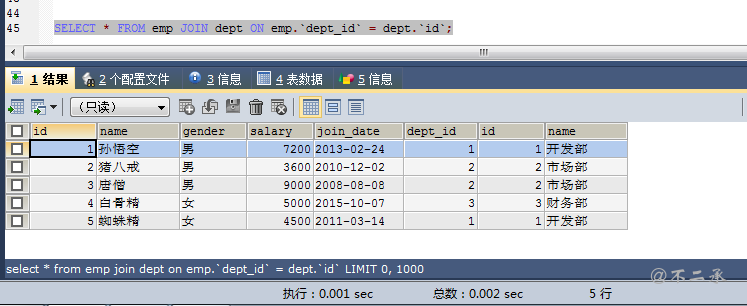
-- 查询所有员工信息和对应的部门信息 select * from emp [inner] join dept on emp.`dept_id` = dept.`id`;
注意事项
从哪些表中查询数据;查询的条件是什么;查询哪些字段。
外连接
左外连接
与显式内连接类似
1
select 字段列表 from 表1名 left [outer] join 表2名 on 条件;
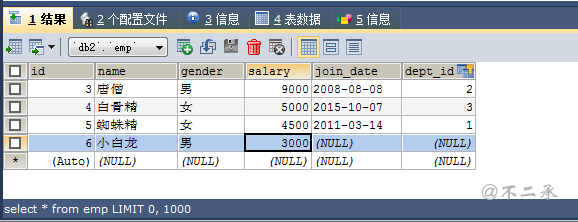
假设新增了一个员工,但是未指定部门(即dept_id为NULL)
1 2 3 4 5 6 7 8
-- 查询所有员工信息,如果员工有部门,则显示部门名称,没有部门则不显示 select t1.*,t2.name from emp t1, dept t2 where t1.dept_id = t2.id;
会发现上述查询并不显示部门为NULL的员工信息。
1 2 3 4 5 6 7 8
select t1.*,t2.name from emp t1 left join dept t2 on t1.dept_id = t2.id;
-- 右外连接 SELECT t1.*,t2.`name` FROM emp t1 RIGHT JOIN dept t2 ON t1.`dept_id` = t2.`id`;
子查询
查询中嵌套查询,称嵌套查询为子查询。
1 2 3 4 5 6
-- 查询工资最高的员工信息 -- 1.查询工资最高是多少?9000 select max(salary) from emp; -- 2.查询员工信息,并且工资等于9000 select * from emp where emp.salary = 9000;
1 2
-- 一步到位,不分开查询 select * from emp where emp.salary = (select max(salary) from emp);
子查询的不同情况
1.子查询的结果是单行单列的:
子查询可以作为条件,使用运算符(>、>=、<、<=、=)去判断
1 2
-- 查询小于平均工资的员工信息 select * from emp where salary < (select avg(salary) from emp);
2.子查询的结果是多行单列的:
子查询可以作为条件,使用运算符in来判断。
1 2 3
-- 查询财务部和市场部所有员工的信息 select id from dept where name = '财务部' or name = '市场部'; select * from emp where dept_id = 2 or dept_id = 3;
1 2
-- 子查询 select * from emp where dept_id in (select id from dept where name in('市场部','财务部'));
3.子查询的结果是多行多列的:
子查询可以作为一张虚拟表来进行表的操作。
1 2 3 4 5
-- 查询入职日期是2011-11-11之后的员工信息和部门信息 -- 日期可以直接使用逻辑运算符来判断大小 select * from emp where emp.join_date > '2011-11-11';-- 作为虚拟表 select * from dept t1,(select * from emp where emp.join_date > '2011-11-11') t2 where t1.id = t2.dept_id;